




Linear Regression Model with a Randomly Censored Predictor: Estimation Procedures
Folefac D Atem1* and Roland A Matsouaka2
1Department of Biostatistics, University of Texas Health Science Center, USA
2Department of Biostatistics and Bioinformatics & Duke Clinical Research Institute, Duke University, USA
Submission: December 29, 2016; Published: March 30, 2017
*Corresponding author: Folefac D Atem, Department of Biostatistics, University of Texas Health Science Center, Houston, TX, USA,Tel: 214-648-1080; Email: Folefac.D.Atem@uth.tmc.edu
How to cite this article: Folefac D Atem, Roland A Matsouaka. Linear Regression Model with a Randomly Censored Predictor: Estimation Procedures. Biostat Biometrics Open Acc J. 2017;1(1): 555556. DOI: 10.19080/BBOAJ.2017.01.555556
Abstract
We consider linear regression model estimation where the covariate of interest is randomly censored. Under a non-informative censoring mechanism, one may obtain valid estimates by deleting censored observations. However, this comes at a cost of lost in formation and decreased efficiency, especially under head censoring. Other methods for dealing with censored covariates such a signoring censoring or replacing censored observations with a fixed number, often lead to severely biased results and are of limited practicality. Parametric methods based on maximum likely hood estimation as well as semi parametric and non parametric methods have been successfully used in linear regression estimation with censored covariates where censoring is due to a limit of detection. In this paper, we adapt some of these methods to handle randomly censored covariates and compare them under different scenario store cently developed semiparametric and non parametric methods for randomly censored covariates. Specifically, we consider both dependent and independent randomly censored mechanisms as well as the impact of using an on parametric algorithm on the distribution of the randomly censored covariate. Through extensive simulation studies we compare the performance of these methods under different cenarios. Finally, we illustrate and compare the methods using the Framingham Health Study data to assess the association between low\density lipo protein (LDL) in off spring and parental ageaton set of a clinically-diagnosed cardiovascular event.
Introduction
Modeling continuous outcome data using linear regression usually assumes in theory that the values of the covariates are fully observed. However, in practice and especially for any large dataset, it is unlikely that complete information will be available for all study participants. The issue of censored data is ubiquitous and affects many studies and permeates a wide range of research areas, including medicine, economics, and social sciences. Multiple reasons lead to in complete observations in a data set including on response, attrition, and absence of even to interest. Usually during the design, implementation, and data collection phases of a study, efforts are made to minimize the occurrence of incomplete data whenever possible and, when unavoidable, to understand the reasons for such a discrepancy in order to handle the available data adequately and run appropriate statistical analyses. Although there is an extensive literature on missing data [1-3] and censored outcomes, [4-6] only a small number of paper shave explored scenario in which the covariate is censored [7-10].
Arguably, the in adequacy of linear regression models on censored outcome variables has sparked an interest in alternative methods, and subsequently has led to major developments of regression models for survival analysis for decades. Extensive literature has been published regarding censored outcomes, especially in studies of time- to -even to us comes where censoring is due to loss of follow-up, dropout, or study termination [4-6].
While there is a vast literature on censored outcomes and different related method shave been discussed extensively, only a limited number of papers have focused on the issue of censored covariates. Ignoring or using a wrong approach to account for the censored nature of a covariate in regression model estimation can lead to analytical issues and spurious results [9-11]. It is important that censored covariates be recognized, acknowledged, and handled appropriately to produce reliable results [12-20]. However, the vast majority of literature on censored covariates has focused on censoring due limit of detection or type 1 censored covariates where observations of the covariate below such a limit cannot be measured or detected, but recorded at or less than the limit of detection value [11,12,21-26]. Only a handful of publications have investigated the implications of randomly censored covariates where some observations of the covariate are censored at varying censoring time points [8,20,27-29]. Censored covariate measurements arise when, for some participants in a study, the as curtained information of interest has not yet occurred (or will not occur) at the time of assessment.
This is due to a lag between the time when a covariate is measured (usually) and the occurrence (or non-occurrence) of an event of particular interest that needs to happen for such a measure to be available and assessed. For instance, Clayton [8] investigated family an aggregation in chronic disease incidence and modeled the possible influence that parental age at onset of a given disease might have on an individual's risk of succumbing to a particular disease. Using the Framingham Heart Study an ongoing multi generation all and mark study designed to identify factors and characteristics that contribute to the development of cardiovascular disease (CVD) and other diseases through longterm, active surve alliance and monitoring Atem & Mat souaka [6] studied the impact that age at onset of clinically-diagnosed cardiovascular events in parents may have on the onset of cardiovascular events among offspring.
In both cases, even if important factors have been thoroughly measured for both parents and their offspring, it is unlikely that all parents have had or will have developed the disease of interest at the time of investigation. This means that the variable" parental age at onset of a given disease" is guaranteed to be censored, i.e., not fully observed. Therefore, it is extremely important in any statistical analysis to account for the fact that the variable of interest is censored for some participants.
In theory, there are many ways to address the issue of censored covariates in data analyses. From a practical point of view, however, the most important questions are: When and under what conditions can one safely consider the problem of censored covariates to be trivial? How can current methods be applied and under what conditions can one expect (asymptotically) unbiased and meaningful results? In general, in appropriate handling of censored covariates may affect the type I error [11], yield biased results, hinder the power to detect any meaningful treatment differences, or lead to loss of efficiency in estimating the coefficient parameters of are aggression model [10].
Complete case analysis, where by observations with censored covariate values are discarded (on purpose or through a soft ware default option), is the most commonly used method. When the sample size of the data is large, the censoring mechanism is independent of the outcome, and the proportion of censored data is relatively small, complete case analysis of the data can be employed safely [1,2] since the impact t of censored observations on the analysis of the data may be negligible. In that case the complete-case analysis yields valid (consistent and a asymptotically unbiased) estimates for regression coefficient parameters.
However, under moderate to heavy censoring of data there might be a substantial loss of efficiency due to the reduction in the sample size and the significant loss of information on other fully observed covariates and on the outcome measures of the deleted observations [9]. Further-more, when the censoring mechanism is informative, using a complete-case analysis can lead to biased results which are in part exacerbated by the losses of information and efficiency Case analysis can lead to biased results which are in part exacter bated by the losses of information and efficiency increase stricting the analysis so Lely to truly observed covariate measures may introduce some imbalance in the data set in a way that misrepresents the population under study.
When the issue of censored covariate is not ignored all together, simple substitution methods (or to be more accurate adhoc fill- in methods) where censored observations are replaced by the overall mean or median of the observed variable or, alternatively, by a constant are frequently used because they are simple, easy to understand, are easy to implement. Unfortunately, they may lead to substantial biased estimates and in accurate conclusions [13,21,24,25,30-32]. Sever a nontrivial statistical methods have been developed specifically to input censored covariates and estimate regression coefficient parameters in a model with a censored covariate [33,34] Some of these methods, known as parametric methods, use maximum likelihood estimation (MLE) under the assumption that the covariate follows a specific distribution [7,10,16,18,34-38].
For example, when such a distribution as assumption is plausible, Richardson & Ciampi [17] proposed using MLE and input censored observations with E (X|X<ξ) in the context where measurements of the covariate, X, are left-censored due to limit of detectionξ. However, this approach has some limitations, especially when the censored covariate is correlated with other covariates [34,35,37,38,39].
As we know, an MLE method relies on a parametric distribution assumption of the censored covariate, i.e., the postulated distribution is assumed to be true and correctly specified. It is less reliable when the distribution assumption is in corrector when the data set is so small that it becomes question able whether the assumed distribution fits the data well. In that case, a semiparametric model that makes weaker parametric distribution as assumptions or, even better, a nonparametric method that does not assume any specific distribution model at all is preferable [15,34,35].
As we previously mentioned, most of these methods highlighted above have been developed to account for type I censoring or limit of detection and are typically developed for left-censored covariates. Nevertheless, it is fairly straight forward to adapt the methods for a limit of detection data or type I censored covariate to a right-censored covariate. However, to the best of our knowledge, no such parametric approach employed for type I censored covariates has been extended to handle a randomly censored covariates. In addition, barring a few papers on dependent (randomly) censoring mechanism [20], the vast majority of published methods for type I censoring rely on the assumption that the censoring mechanism is independent of the outcome in interest [12,15,19,32].
Our primary objective in this paper is to adapt a parametric method proposed in linear regression models with a type I censored covariate to the case in which a covariate is randomly censored covariate. We use simulation studies to compare this newly developed method to the methods proposed by Sampene & Folefac [20] in which randomly censored covariate values are replaced by a nonparametric and a semiparametric estimations of E (X | X ≥t) or E (X | X ≥t,Y), where t denotes the maximum observation time for the variable X, and the outcome of interest Y. For this purpose, we will consider both dependent and independent censoring mechanism, which occurred depending on whether such a censoring mechanism depends or not on the outcome of interest. Furthermore, we will also compare the fore mentioned non parametric estimation method to the commonly used deletion or complete-case analysis and give recommendations on the methods of estimation based on our simulation results. We begin in Section [21] by presenting parametric c and non-parametric methods used in the censored covariate literature. We then introduce the methods proposed by Sampene & Folefac [20] to handle randomly censored covariates. In Section [18] we run simulation studies to compare each of the discussed methods as well as the complete- case analysis method. Finally, we apply these methods in Section [16] to the Framingham Offspring Study to assess the influence of parental age at onset of cardiovascular disease on the systolic blood pressure of their offspring.
Notation and Methods
We consider n study participants independently sampled from a referenced population. Let Yi, Xi and Ci be, respectively, the continuous outcome variable, the potentially censored covariate (from which we are interested in making inferences), and the right censoring variable, where i ind exes subjects. Due to the right censoring in the covariate X, for each participant ti, we observe the vector (Yi,Vi,δ i)T Where min(Xi,),i=1,2,.....n.The linear regession model is given by Y=β0+β1X+εWhere the parameter coefficents ᵦ0 and ᵦ1 are intercept and slope, respectively. The random errorɛis assumed to be independent of X and follows a normal distribution with mean 0and variance σ2 i.e.ɛ~N(0,σ2). We consider two different cases of censoring mechanisms. In the first case, we assume that the censoring mechanism is non- informative, i.e., C is independent of the outcome Y. For the second case, we assume that the censoring mechanism depends on the outcome Y, in a sense that there is some known point c0 ϵR such that the random variable C followes a distribution characterized by the distribution function G0 when Y< c0and by the distribution function G1 When Y≥C0. For simplicity and demonstrative purposes, we limit our discussion to cases with no additional covariates. If, in practice, the data a than d contain a set of additional fully- observed (i.e. non-censored) covariates, Z, the method discussed here could easily be extended to accommodate such covariates.
Parametric Method
Maximum likelihood estimation
A parametric method assumes an underlying distribution of the population from which the data at than d were sampled and uses the maximum likelihood estimation method to draw inference. Suppose that the censoring C is independent of Y; the simplies Xi and ɛi are independent. Therefore, the distribution of Y is a product of the distributions of Xi and £i. The likelihood L of Y is made up of two components; one based on the uncensored observed (X1,........Xm)and the other on the right censored (Xm+1,... ,Xn ]: 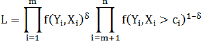
With δ=1 if X is observed and δ=0 if X is censored, I ,...,n.The maximum likelihood estimate of the unknown regression parameter corresponding to the censored covariate X is derived from the log-likely hood function 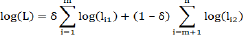
Where log(lil]=log[f(Yi,Xi]] and log(I2]=log[f(Yi,Xi˃ci]]. Suppose that X follows a normal distribution with mean μ2 xand variance σ2x, we have 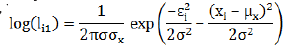
For the second component, consider Φ(x) the cumulative Gaussian distribution function and define εi=yi-β0-β1and(iμ_x )=y_i-β_0-β_1 μ_x and Q=√(σ_X2+β2σ2). we show in the Appendix that
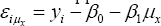
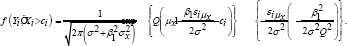
When censoring is dependent as described above, Ci and Y are dependent. The likelihood can be expressed as
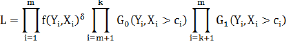
Where the data is made of fully observed Xj,...,xm and right censoredxm+1,...,xn.The censored component is divided intoxm+1,...,xk and xk+1...,xn componentswithassociateddistributionG0 andGj respectively, as in equation (2).
Overview of the nonparametric methods
As stated in the introduction, most of the methods described in published literature that examine the issue of covariates are subject to the limit of detection .Prior to the late1990's,the most common approach to handling such censored covariates was the complete-case analysis method. Alternatively, several naive adhoc alternative methods have been proposed, including substitution methods, which consist of replacing censored covariate values with either a function of the limit of detection, ξ, e.g.ξ,√2ξ2ξ, [19] or the mean of the observed covariate measures (mean substitution) [37] as well as dichotomizing the potentially censored covariate into a binary covariate [18,13] In evitable, each of these adhoc methods leads to a biased estimation ofβ 1.
For instance, Helsel investigated the use of the senaive substitution methods and concluded that they are inefficient and have no mathematically plausible backing [14]. The extent of the inefficiency depends on the extent and the severity of censoring (i.e., the distance between the limit of detection or random censoring value and the natural limit for X) of censoring. Finally, Ate metal [8,27] explored additional non-parametric methods, based on multiple imputation approach, but concluded that these methods were not efficient when applied to the cases of dependent censoring. Recently, Sampene and A team proposed two conditional multiple imputation methods for estimation and inference [20]. The under pinning's of these methods involve replacing the randomly censored values Xi by estimates of E(Xi | X i>t), for i=m+1,...,n. In the absence of additional covariates ,the former is determined via a Kaplan-Meier estimator and performs well when the correlation between X and Y is weak. When the correlation between X and Y is strong, similar to case of missing covariate the outcome of interest is included in the imputation E(X i | Xi >t,Yi) [1].
This conditional imputation involving outcome Y, unlike the imputation not involving Y used estimates from the Cox proportional hazard hence the name Cox Multiple Imputation. To estimate the corresponding variance of[ β]_1for inference, Sampene and A team suggested using either a conditional multiple imputation or a conditional single imputation along with a boot strap re sampling procedure to correct for the under estimation of the variance in here n t to the single imputation [20]. In doing so, we showed that these improvements to the complete-case analysis method result invalid inferences regardless of whether the censoring mechanism is dependent or independent of the outcome. Furthermore, using simulation studies, they demonstrated that the multiple imputation method dissimilar to the conditional single imputation with boot strap re sampling.
In then extsection, we will run simulation studies to compare the complete-case analysis, parametric, mean imputation, naiveadhoc, conditional single imputation, conditional multiple imputation and Coxmultiple imputation methods. It is worth mentioning that Coleetal & Nieetal (2009). Have explored the parametric approach for type1 censoring. They showed that this approach is very efficient for limit of detection data. However, it is worth exploring how well this parametric approach works compared to others nonparametric approaches when censoring is random [35].
Monte carlo simulations
Data generation and simulation setup: We assumed that the true linear regression model is given by Y= β 0,+βX+ε, with (β0,β1 )=(1,0.5) ands ~N(0,1). The variable X as well as the censoring variable distribution were generated from a two- parameter We I bull distribution
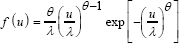
Where θis the shape parameter so known as the we I bull slope, with θ>0 and λ,λ>0, is the scale parameter. More precisely, we generated K=2000 samples of size n=100 and n=500 respectively, and choose ε ~N(0,1) in each case. For independent censoring mechanism, we considered the following distribution
X~Weibull((3/4,1)/4)and C~Weibull(1,q)forq=1.50 and0.35
X~Weibull(1,1/4)and C~Weibull(5/4,q)with q=1 and 0.4
X~Weibull(2,1/4)and C~Weibull(9/4,q)with q=0.50 and 0.30.
The selected values of q allowed us to obtain, respectively, 20% and 40% censoring. Under dependent censoring, we defined the corresponding mechanism such that C=C1 if Y>1.02 and C=2 if Y≤1.02. We also considered the following data generating distributions to obtain 20% and 40% censoring: X~Weibull(2,1/4),C1~Weibull(9/4,q)andC2~Weibull(10/4,q) with q=0.50 and 0.30, respectively.
Simulation results
Table1-4 summarize the results of the four sets of simulations performed for light censoring (20%) and heavy censoring (40%) in terms of the following quantities:
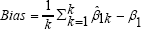 ,which is the (overall) deviation of a parameter estimate from the true parameter β1=0.5, where β1k is the estimate from the k-th generated data set;
,which is the (overall) deviation of a parameter estimate from the true parameter β1=0.5, where β1k is the estimate from the k-th generated data set;
Empirical standard error, SE(β1 ), of the estimateβ1 overall K simulation data sets
Simulation error, i.e., the average of model-based standard errors;
Mean squared error (MSE), which is the expectation of the squared aviation of a parameter estimate from the truth. It is equal to Bias2+SE(β 1 );
Cover age probability which is the proportion of simulated samples for which the 95% confidence interval )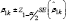 includes the true coefficient β1=0.5, fork=1,...,K.
includes the true coefficient β1=0.5, fork=1,...,K.
Table 1 & 2skewed (Figure 1), the parametric approach results in large biasshow that when the distribution of X is highly skewed (Figure 1), the parametric approach results in large bias and MSE as compared to the conditional multiple imputation approach. Although the complete case is unbiased, deleting observations reduces the sample size, which results in an increased standard error and larger MSE as compared to both the maximum likelihood and the conditional multiple imputation methods. Despite being unbiased, both the complete case and the mean substitution methods are inefficient with higher MSE as compared to the maximum likelihood approach, conditional multiple imputation and the Cox multiple imputation approach. The single conditional imputation is unbiased and is more efficient than the mean imputation with smaller MSE because its underestimates the standard error when imputed values are used as true values with no uncertainty. All approaches resulted in acceptable cover age probabilities.
Tables 3[16] show that, when the distribution of X is close to normal (Figure 1, the maximum likelihood approach results in smaller bias and standard error. The log likely hood [40] is derived under the normal distribution as assumption. Therefore, the distribution of X in (Table 3 &4), Is close to the true distribution from which the maximum likelihood method is based, provides a better and a more efficient parameter estimate than the multiple imputation methods. The standard error and MSE is smaller than that of both the conditional multiple and Cox multiple imputation approaches. The other imputation methods are less efficient and more biased. Overall, it is worth mentioning that the Cox multiple imputation is more efficient than the conditional imputation when the data is well powered. As the sample size increases, this Cox multiple imputation is very efficient, which might be due to the fact that this approach uses one additional parameter Y in the imputation model as compared to the Kaplan Meier based conditional imputation that does not involve the outcome in the imputation model.
Illustrative example
Association between parentage of cardiac events and low density lipoprotein (LDL) in offspring: According to the American Heart Association cardiovascular disease (CVD) is a multi-faceted disease that affects the heart or blood vessels. CVD includes hypertensive, rheumatic, congenital, and vulvar heart diseases as well as cardio my apathies, heart arrhythmias, carditis, aortic aneurysms, peripheral artery disease, venous thrombosis, coronary death, myocardial infarction, coronary in-sufficiency, angina, is chemic stroke, hemorrhagic stroke, transient is chemic attack ,peripheral artery disease, and heart failure. It is the global leading cause of death, accounting for over 30% of all deaths worldwide-approximately 17.3 million deaths per year. In the United States, someone dies from CVD every 39 seconds, with most of those deaths being attributed to coronary heart disease [40-42]. Though the death rate due to CVD has decreased slowly over the last 30 years, death from heart disease remains the leading cause of death in the United States, and caring for patients with poor cardiovascular health continues to be one of the largest burdens on the health care system today. From 1990to2009, CVD ranked first in the number of days for which patient received hospital care [43], yet 72% of Americans do not consider themselves at risk for heart disease [40].
Association have long been established between CVD and a wide variety of risk factors, including non-modifiable variable such as family history [44-50]. Blood levels of low density lipoproteins (LDL), one of the five major groups of lipo proteins categorized by density, are regarded as a strong predictor of CVD. To illustrate the methods proposed in this paper, we study the association between LDL in offspring and age at onset of clinically diagnosed cardiovascular even tin parents, using data from the Framingham Heart Study data base and looking at both the Original and Offspring cohorts [51].
The Framingham Heart Study (FHS) is an ongoing prospective study of the etiology of cardiovascular disease, among other prevalent diseases. The study began in 1948 and enrolled 5, 209 participants (55% women) aged 28 and 62 years old residing in Framingham, Massachusetts a spart of the original cohort who have been followed up to the present. In 1971, the Framingham Offspring Study was established with a sample of 5, 124 men and women aged 5to70 years old who were either (genetic or adoptive) offspring or spouses of offspring of the original cohort [52-54]. Study participants are examined routinely to update their health status information and potential risk factors. Standard clinical examinations included physician interview, physical examination, and laboratory tests, and continue to the present. Participants in the original cohort have been followed biannually; there were 40 participants during the 32nd Exam visit held in 2012- 2014. In the offspring cohort, participants have been followed approximately every four years. The Offspring Examination Cycle 9 covered the years 2011 to 2014 and had 2430 participants.
In this example, we performed two separate analyses, one for each parent, to evaluate the relationship between ages of CVD in parents and log(LDL)in offspring. Data gathered from the original cohort (Exam12 (1971-1974); 3, 261participants) and the offspring cohort (Exam1 (1971-1975); 5, 124 participants) were used. We deleted all missing data and restricted the LDL to physician recorded values; this reduced the sample size ton= 2622 (1,401 mothers and 1,221fathers).Of the 1401 mothers in the final data set, 907 of them (i.e., 35.26%) experienced a cardiovascular event whereas 909 (i.e., 74.45%) out of 1,221 fathers experienced a cardiovascular event. The median age of CVD was 66years and 63years for mothers and fathers, respectively.
Results of the data analyses are provided in (Table 5 &6). The results for the complete- case analysis, mean substitution, maximum likelihood, conditional single imputation and the conditional multiple imputation are consistent with the simulation results. With a larger sample, the assumption of normality for the censored covariate is met and the parametric method provides better estimates along with smaller standard error. On the other hands, the results from the adhoc substitution methods are inconsistent with the simulation results. This is because there is no scientific base for such substitutions.
Conclusion
Most of the literature on censored covariates deals with the issue of limits of detection, the point at which observations below this limit cannot be measured or detected and are instead recorded at the limit of detection value. [13,21,25] In this paper, we considered the estimation of linear regression models when the covariate of interest is randomly censored. We evaluated non parametric conditional imputation methods based on the Kaplan-Meier estimate to impute a censored covariate. We compared this nonparametric approach based on Kaplan-Meier to the regression from the full data (without censoring), the complete-case analysis, a naive adhoc substitution (replacing censored values by the mean of the observed covariate values) and the maximum likelihood approach.
Parametric estimators were determined via maximum likelihood estimation method based on an under lying distribution as assumption of the censored covariate. Throughout our simulations, we demonstrate that then alive adhoc substitution method provides biased estimation of the regression parameter of the censored covariate. As Helsel pointed out, these substitution methods area kin to fabricating data; they don't have any theoretical basis and should thus be discouraged [23].
The complete case analysis method is the widely used approach for handling censored predictor sanities easy to implement. The obvious spit fall of the complete case approach is that it potentially sacrifices information by discarding observations. Although, this method leads to unbiased estimates under independent censoring, it can result in a substantial loss of power, especially under moderate to high percentages of censored observations. Under dependent censoring, complete- case analysis may lead to model misspecification due to selection bias if a group of subjects with similar characteristics do not experience the even to fin terestor leave study before its completion.
The mean substitution approach is easy and looks reliable but a detailed analysis of this approach shows it has many short comings. We cannot always guarantee that the mean of the complete case will be greater than the time at censoring. One basic assumption of censored data is that, if the event is to occur, it can only happen after the censored time. Furthermore, this approach does not make use of the available information, that is, the time at censoring. Using parametric methods requires prior knowledge or postulating a distribution model for the censored covariate. When the postulated parametric distribution of the censored covariate corresponds to the true distribution, the maximum likelihood estimation method and then on parametric method via Kaplan Meier estimation all provides consistent estimates, under independent censoring. Under dependent censoring, if the distribution of X and C are similar, these methods are efficient; however, if the distribution of X and C are dissimilar the MLE approach will be highly inefficient (as shown in section 2.1). Therefore, we propose the use of Kaplan Meier non parametric imputation in absence of prior knowledge of the distribution of censored covariate when such a distribution cannot be accurately as certained. On the other hand, if the sample size is large and the distribution of X is a member of the exponential family, the MLE approach can be suitable.
References
- Wang HJ, Feng X (2012) Multiple imputation form-regression with censored covariates Journal o f the American Statistical Association 107(497): 194-204.
- Kong S, Nan B (2016) Semi parametric approach to regression with a covariate subject to detection limit. Biometrika 103(1): 161-174.
- Schisterman EF, Vexler A, Whitcomb BW, Liu A (2006) The limitations due to exposure detection limits for regression models. Am J Epidemiol 163(4): 374-383.
- Clayton DG (1978) A model for association in bivariate life tables and its application in epidemiological studies of family altendency in chronic disease incidence. Biometrika 65(1): 141-151.
- Atem FD, Qian J, Maye JE, Johnson KA, Betensky RA (2016) Multiple imputation of a randomly censored covariate improves logistic regression analysis. J Appl Stat 43(15): 2886-2896.
- Atemand F, Matsouaka RA (2016) Survival analysis with a randomly censored covariate. T echnical report.
- Helsel DR (2005) None detects and data analysis Statistics for censored environmental data. Wiley Interscience pp. 254.
- Kleinand JP, Moeschberger ML (2003) Survival analysis. Techniques for censored and truncated data, Springer Science & Business Media.
- Donahue R, Bloom E, Abbot tR, Reed D, Yanok (1987) Central obesity and coronary heart disease in men. The Lancet 1(8537): 821-824.
- Dawber TR, Moore FE, Mann GV (2015) Coronary heart disease in the Framing ham study Int J Epidemiol 44(6): 1767-1780.
- Atemj, QianJ, Maye E, Johnson KA, Betensky RA (2016) Linear regression with a randomly censored covariate:application to analzheimer's study. Journal of the Royal Statistical Society: Series C (Applied Statistics) 66(2): 313-328.
- Helsel DR (2006) Fabricating data: how substituting values for non detects can ruin results ,and what can be done about it. Chemosphere 65(11): 2434-2439.
- Kannel W, Dawber T, Thomas HJr, Namara PM (1965) Comparison of serum lipids in the prediction of coronary heart disease Framingham study indicates that cholesterol level and blood pressure are major factors in coronary heart disease; effect of obesity and cigarette smoking also noted. R I Med J 48: 243-250.
- Schisterman EF, Vexler A, Whitcomb BW, Liu A (2006) The limitations due to exposure detection limits for regression models. Am J Epidemiol 163(4): 374-383.
- Neaton JD, Wentworth D (1992) Serum cholesterol, blood pressure, cigarette smoking, and death from coronary heart disease over all findings and differences by age for 316099 white men. Multiple Risk Factor Intervention Trial Research Group. Arch Intern Med 152(1): 5664.
- Lee S, Park S, Park J (2003) The proportional hazards regression with acensored covariate. Statistics & probability letters 61(3): 309-319.
- https://www.heart.org/idc/groups/heartpublic/@wcm/@adt/ documents/downloadable/ucm_441512.pdf
- Lipsitz S, Parzen M, Natarajan S, Ibrahim J, Fitzmaurice G (2004) Generalized linear models with sened covariate Journal of the Royal Statistical Society: Series C Applied Statistics 53(2): 279-292.
- Mahmood SS, Levy D, Vasan RS, Wang TJ (2014) The Framingham Heart Study and the epidemiology of cardiovascular disease. A historical perspective. Lancet 383(9921): 999-1008.
- Keysetal A (1970) Coronary heart disease in seven countries. Circulation 41(1): 186-195.
- Little RJ, Rubin DB (2014) Statistical analysis with missing data. John Wiley & Sons, USA.
- Albert PS, Harel O, Perkins N, Browne R (2010) Use of multiple assays subject to detection limits with regression modeling in assessing the relationship between exposure and outcome. Epidemiology 21(l4): 35-43.
- Richardson DB, Ciampi A (2003) Effects of exposure measurement error when an exposure variableis constrained by a lower limit. Am J Epidemiol 157(4): 355-363.
- Arunajadai G, Rauh VA (2012) Handling covariates subject to limits of detection in regression. Environmental and ecological statistics 19(3):369-391.
- Nie L, Chu H, Liu C, Cole SR, Vexler A, et al. (2010) Linear regression with an independent variable subject to a detection limit. Epidemiology 21(suppl 4): S17-24.
- Wu H, Chen Q, Ware LB, Koyama T (2012) A Bayesian approach for generalized linear models with explanatory biomarker measurement variables subject to detection limit: an application to acute lung injury. J Appl Stat 39(8): 1733-1747.
- Lagakos S (1979) General right censoring and its impact on the analysis of survival data Biometrics 35(1): 139-156.
- https://www.cdc.gov/nchs/data/hus/hus10.pdf
- Manson JE, Colditz GA, Stampfer MJ, Willett WC, Rosner B, et al. (1990) A prospective study of obesity and risk of coronary heart disease in women. N Engl J Med 322(13): 882-889.
- Hornungand RW, Reed LD (1990) Estimation of average concentration in the presence of non detectable values. Applied occupational and environmental hygiene 5(1): 46-51.
- Howard BV, Robbins DC, Sievers ML, Lee ET, Rhoades D, et al. (2000) LDL cholesterol as a strong predictor of coronary heart disease in diabetic individuals with insulin resistance and low LDL: The strong heart study Arterioscler. Arterioscler Thromb Vasc Biol 20(3): 830-835.
- Rigobonand R, Stoker TM (2007) Estimation with censored regressors: Basic issues. International Economic Review 48(4): 1441-1467.
- Keil U (2000) Coronary artery disease: theroleo flipids, hypertension and smoking. Basic Res Cardiol 95(1): I52-I58.
- Rigobonand R, Stoker TM (2009) Bias from censored regressors. Journal of Business & Economic Statistics 27(3): 340-353.
- Vexler A, Tao G, Chen X (2015) A toolkit for clinical statisticians to fix problem s based on biomarker measurements subject to instrumental limitations: From repeated measurement techniques to a hybrid pooled-un spooled design. Methods Mol Biol 1208: 439-460.
- Angelo GD, Weissfeld L (2008) An index approach for the Cox model with left censored covariates. Stat Med 27(22): 4502-4514.
- Kleinbaum DG, Klein M (1996) Survival analysis. Springer-Verlag New York, USA, ISBN: 978-0-387-21645-4.
- Cole SR, Chu H, Nie L, Schisterman EF (2009) Estimating the odds ratio when exposure has a limit of detection Int J Epidemiol 38(6): 16741680.
- Little RJ, Rubin DB (2014) Statistical analysis with missing data. John Wiley & Sons, USA.
- Manson JE, Colditz GA, Stampfer MJ, Willett WC, Rosner B, et al. (1990) A prospective study of obesity and risk of coronary heart disease in women. N Engl J Med 322(13): 882-889.
- Little RJ (1992) Regression with missing X's: a review. Journal of the American statistical Association 87(420): 1227-1237.
- Bernhardt W, Wang HJ, Zhang D (2014) Flexible modeling of survival data with covariates subject to detection limits via multiple imputation. Comput Stat Data Anal 69: 81-91.
- Lee M, Kong L, Weissfeld L (2012) Multiple imputation for left-censored biomarker data based on Gibbs sampling method. Stat Med 31(17): 1838-1848.
- Schisterman EF, Vexler A, Whitcomb BW, Liu A (2006) The limitations due to exposure detection limits for regression models. Am J Epidemiol 163(4): 374-383.
- Angelo GD, Weissfeld L, GenIMS Investigators (2008) An index approach for the Cox model with left censored covariates. Stat Med 27(22): 45024514.
- Schwalm J, McKee M, Huffman MD, Yusuf S (2016) Resource effective strategies to prevent and treat cardiovascular disease. Circulation 133(8): 742-755.
- Lynn HS (2001) Maximum likely hood inference for left-censored HIV RNA data. Stat Med 20(1): 33-45.
- Bernhardt PW, Wang HJ, Zhang D (2015) Statistical methods for generalized linear models with covariates subject to detection limits. Stat Biosci 7(1): 68-89.
- Sampeneand E, Atem FD (2015) Imputing a randomly censored covariat in a linear regression model. Technical report.
- Sattar A, Sinha SK, Wang XF, Li Y (2015) Frailty models for pneumonia to death with a left-censored covariate. Stat Med 34(14): 2266-2280.
- Helsel DR (2005) More than obvious: better methods for interpreting non detect data. Environ Sci Technol 39(20): 419A-423A.
- Langohr K, Gj'mezG, Muga R (2004) A parametric survival model with an interval-censored covariate Statistics in medicine 23(20): 31593175.
- Austin PC, Hoch JS (2004) Estimating linear regression models in the presence of a censored independent variable. Stat Med 23(3): 411-429.















